
最近糖質制限してて、ピッツァ~食べてない!!!それはさておき、
エンジニアのブログなのに、技術要素が全くない・・・!
どうも、日本一ギャグセンスがあるエンジニア、しゅういちです。
エンジニアなのに、エンジニアっぽい記事を一つも書いていないということで、今日は書いちゃいますよ~!!今後も色々増やしていくつもりです。
最近はPythonがお気に入りなので、Webスクレイピングをやってみたよ。しかもWindows10の環境で。で、結構はまる人がいそうだったので、Webスクレイピングでよく使われるBeautifulSoupというライブラリを使用してはまったところを書いちゃおうと思う。
ライブラリをインストールする場合、Python3.5ではBeautifulSoup4が適応されているから、pip3でンストールする時は注意してくださいね!インストールは基本、
pip3 install Beautifulsoup4
で行けます。。
で、以下書いたコードです。
scraping.py
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://in-sec.xyz")
soup = BeautifulSoup(html,"lxml")
print(soup.findAll("h3"))
結構いろんなところでスクレイピングの記事が書かれていますけど、肝心なところが書いていないっていう(笑)
ちょこっと解説入れますね。
※Webスクレイピングを行う際は、過度なアクセスを行ってしまうと、サーバーの管理者に「攻撃された」とみなされるケースがありますので、十分に気を付けて行ってください。
BeautifulsoupのfindAllはリストで入っている
以下の画像をご覧ください。
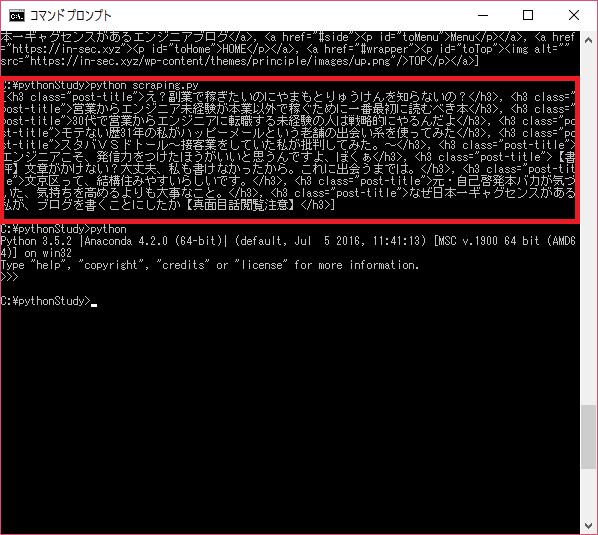
findAllメソッドは、指定したタグすべてを取得するメソッドです。上記ではh3タグを取得しています。
ご覧いただいてもわかるように、リストに一個づつh3タグが入っています。findというメソッドもあるのですけど、プログラムは基本受けから順番に流れます。最初に見つけたh3タグしか見つけることができないのです。findメソッドを使った場合はこういう風になります。
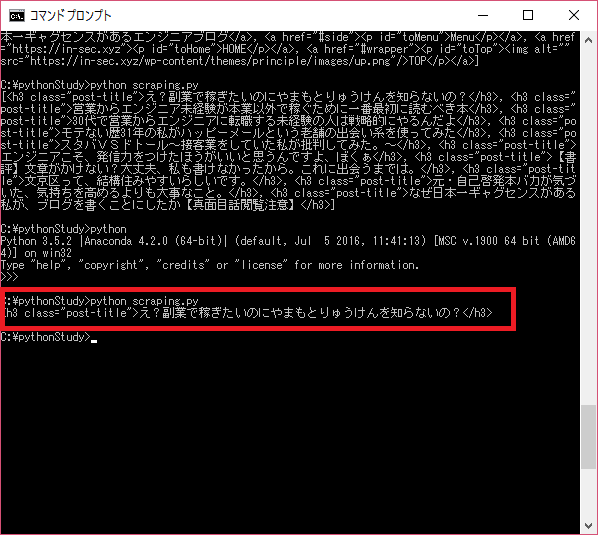
findメソッドを使った後にfindAllメソッドを使う組み合わせもできます。findメソッドはタグのまとまりを取得することができます。まとまりを取得した後に、findメソッドの内部をfindAllメソッドで指定したタグをすべて取得できます。
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://in-sec.xyz")
soup = BeautifulSoup(html,"lxml")
print(soup.find("div",{"class":"post"}))
divタグのclassでpostを取得してます。
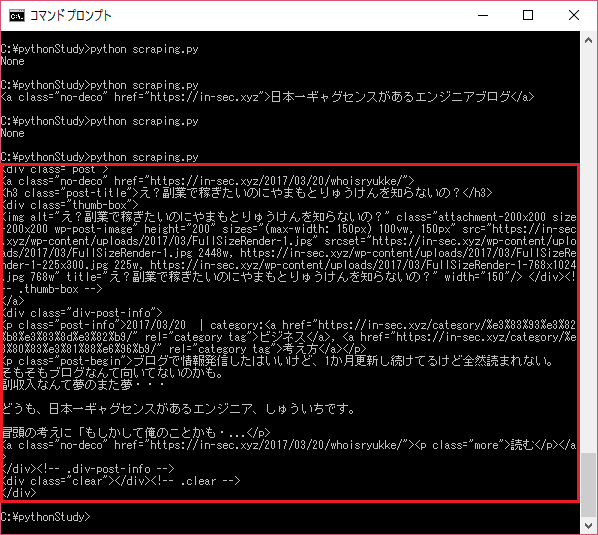
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://in-sec.xyz")
soup = BeautifulSoup(html,"lxml")
print(soup.find("div",{"class":"post"}).findAll("div"))
divタグのpostという名前のclassを指定して、タグのかたまりを取得。そして、findAllで取得した中だけのdivタグを取得する。という感じです。
で、お気づきの方もいると思うんですけど、findAllはResultSetっていうオブジェクトで、タグごとにリスト型に成形されているから、取り出すときはfor文を回るのが良い。以下はタグをのぞいたテキストを取得するコード
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://in-sec.xyz")
soup = BeautifulSoup(html,"lxml")
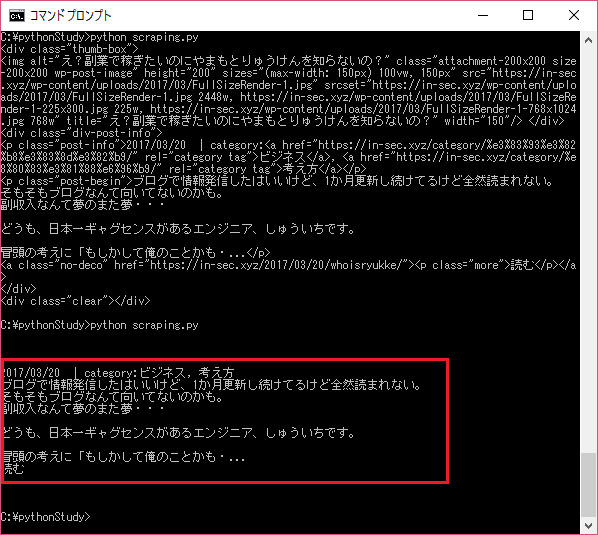
for i in soup.find("div",{"class":"post"}).findAll("div"):
print(i.get_text())
実行結果
まとめ
単一ページを取得するのは簡単だけど、サイト全体とかがちょっと骨折れそう。技術ブログでも、楽しいことが言えるそんな私になります。







コメントを残す